Our first speaker at our July DOXLON was Jeremie Vallee who works as a Lead DevOps at Babylon Health.
During his session he talked about how while Kubernetes and Mesos are all the rage, you don’t necessarily need a complex orchestration layer to start using and benefiting from Docker. He presented how Babylon Health is running its dockerised AI microservices in production, pros and cons, and what they have in store for the future.
In this presentation Jeremie spoke about how Babylon Health is surviving with Docker running in production without using an orchestration tool. Jeremie starts off with explaining the goals of Babylon Health and how they want to provide healthcare more affordably by utilizing technology via their app. Their first idea was to develop a chat bot as the first point of contact for all the patients. The very first version of the chat bot had 8 stateless applications with the idea to use micro service architecture. The reasoning behind that was to build something fast and to build small applications that could communicate together. Another reason was to have smaller teams that were able to share knowledge while developing the application.
While building out this project they had a few criteria which included:
- Multiple languages (Java, Python,…)
- Good dependency management
- Good artifact tracking
- Separate build time/deploy time
- Dev/prod parity
They began to consider all the technologies available that would suit their needs and the obvious choice was Docker as it ticked all the boxes. After they decided to go with Docker, there were a few objectives that they wanted to tick off:
- Fast deployments
- Service routing and authentication
- Monitoring
- High availability
- Scalability
The first thing that they found was Kubernetes and Mesos which looked like a perfect fit. However they also faced a few constraints:
- Time
- Docker beginner level
- No AWS/GCP: not able to use the cloud to store data as they are based in the UK
- Limited resources
They looked for a simple solution and decided to start from scratch by asking themselves what is the minimum that they need to run applications with the objectives that they had. All they needed was a Linux box with Docker on it. In order to make things as simple as possible they used the below command to do a Docker run:
/usr/bin/docker run --rm \
-p 127.0.0.1:8805:7799 \
--env-file /opt/babylon/myapplicationA/environment \
--name myapplicationA myrepo.io/babylon/myapplicationA:master
The problem with the above is that it is a somewhat complicated demand and there were issues with stopping and changing versions. They figured out that they could use systemD to engulf that Docker application and use the application as a service.
They then ran into the issue of how to use the service and for this they had to look around to see what technologies could help them. They ended up going with Kong, which is an open source API gateway. With this they could open a single point of contact and with a different prefix in the URL map it to any application running on the machine.
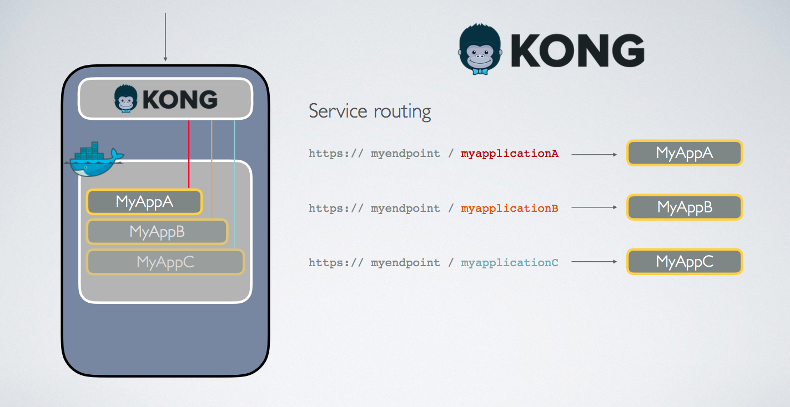
With Kong they were able to have an easy deployment, service routing, and authentication. However, they were still missing out on monitoring. They were most concerned about all their applications having a health check endpoint as well as visualization on their logs. To remedy the situation they began using a tool called Logstash on the box to collect application logs and metrics. The data then gets shipped to Elasticsearch and visualized with Kibana.
With that information they were able to build dashboards:
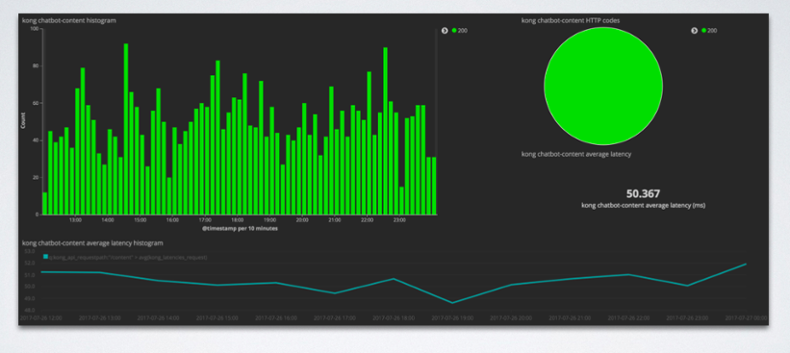
The next boxes to tick off were high availability and and scalability. The answer for this was to add another load balancer on top and continue querying your applications. This was the easiest solution without using proper orchestration tools.
They have been running this solution for about 9 months and it seems to be working out for them. However, there are some limitations:
- HTTP based applications only
- External health checks limited with multiple servers
- Each application must be deployed on all servers
What does the future hold? There are new needs that they face such as:
- 50+ micro services
- GPU based applications
- Queue based applications (Kafka)
- gRPC
- Internationalization
To help with all their needs they’re looking into using the following for the next generation of their infrastructure

In conclusion, they found that they didn’t really need to have a big orchestration system when starting with Docker. Even though they couldn’t run on AWS or Google cloud they were still able to make it work. If you can’t use Kubernetes from the start then just keep it simple and try to see how to make it available for everyone. The most positive outcome was that the chat bot was able to get out in the world fairly quickly and they were able to get feedback and they’re ready to take it to the next level.
This content came from DevOps Exchange London (#DOXLON), a monthly DevOps Meetup in London.
If you’d like to speak at a future DOXLON or join the Meetup, please visit the DOXLON Meetup page.