Part 1: Kafka
Sometimes it seems like the applications are octopus shaped and multidimensional.
Some Background
Running applications in the cloud is the end goal of many a company these days and on the face of it, it seems easy. But getting into it a bit, lots of edge cases come up and you start to realize a lot of applications are fundamentally unsuited to living in a conventional cloud infrastructure. Saved state, obscure clustering requirements, service discovery and high availability requirements all join up to leave you wondering if some bits of software were designed specifically to make your life as a DevOps engineer harder.
In this blog series I will go over some of the techniques we have used at Outlyer to overcome some of these problems and fit large parts of our infrastructure into AWS auto scaling groups (ASGs).
A Common Set of DevOps Tools!
At Outlyer we use some tools to help/hinder our progress to DevOps utopia:
-
Terraform to control our AWS infrastructure. It has its fair share of drawbacks and can be quite frustrating if you are trying to do anything non-trivial but it’s still the best there is. We make heavy use of modules to keep the code reasonably clean and DRY across the all environments.
-
Chef bootstraps nodes, both those in and out of an ASG. It’s consistent, well understood and prevents a sprawl of random user-data scripts written in the scripting language that took the engineers’ fancy at that day. We use Chef-solo exclusively, no Chef-server. Cookbooks are packaged into a Debian package and installed on the AMI at build time so the instances always come up with consistent versions of the configuration.
-
Consul is used for service discovery and DNS. Consul fits with AWS extremely well, both it’s servers and clients finding their buddies through the AWS API, by a tag query. You just assign a tag to the instances you want to form part of a Consul cluster and away they go (given correct IAM permissions). There is no tricky cluster configuration and it all just works. Services are defined on the Consul ‘client’ (i.e your application, database) nodes and Consul checks the status of the service with a health script or attempts to TCP connect or whatever. If the service goes down Consul takes it out of it’s DNS endpoint so dependents can’t connect to broken nodes.
-
Outlyer. Finally Monitoring; We are a monitoring company and we use our own monitoring product to monitor our product that monitors other people’s stuff for them! Before you disappear right down the rabbit hole there, we run an isolated environment and there is a lot of cross-monitoring between environments. That way we always get alerted if something fails.
To ensure we are always on our latest Outlyer-agent a single Chef cookbook runs on a cron job to update to latest every half hour. It’s the only part of Chef that gets run on ASG boxes once they are up and keeps the agent up to date. Cheffing nodes in an ASG may be controversial but in this instance having our latest bleeding edge agent on things to test is invaluable. The alternative of re-building new AMIs for every agent release doesn’t bare thinking.
In the Beginning, There Was Kafka
Kafka is a fairly fundamental part of our infrastructure at Outlyer and was one of the first pieces put into AWS. Initially we tried Kinesis, but it doesn’t support all the feature we require of Kafka. Kafka is super high performance, but you will pay for that either in uptime and lack of High Availability or Operations time and effort.
We really need it to stay up and never lose its data and it has taken a little trial and error to get to where we are happy with it. There are still improvements that can be made!
Or Maybe Zookeeper
Kafka has the additional requirement for Zookeeper to manage the Kafka cluster and Zookeeper has to be clustered too.
To make matters really hard in the cloud, Kafka nodes all require individual unique broker IDs to be set; Zookeeper nodes need a full list of the IP addresses of all the other Zookeepers. DNS names are no good here since Zookeeper will only resolve them once on startup.
Initially to try and make matters easier, we built our clusters outside ASGs, on plain EC2 instances.
There was lots of ${count.index} being passed around Terraform allowing us to derive the various IDs and some post-install
population of IP address lists. Eventually, we had something that came up and the services worked.
Not using ASGs in AWS isn’t really a solution though. Instances can come and go, and we want infrastructure that heals itself so we won’t get woken up in the night to re-run some Terraform you barely remember months later when the thing stops working randomly when a node goes away. It’s easy to let your Terraform go stale on those instances that don’t often cycle. Importantly here, ASGs provide replacement of instances when AWS decide to pop one out from under your feet.
The breakthrough came a few iterations later when we started looking at Zookeeper as it’s own entity, rather than an annoying but necessary bolt-on for Kafka. We solved the problem of needing an IP address list by picking an IP address range from our network, and assigning those IP addresses statically to the Zookeeper boxes.
Now the Zookeepers still hadn’t made it into an ASG, but the approach was a step closer to that; IP addresses no longer need to be pushed through from Terraform. They are calculated from the AZ the box is running in and we use an offset to get them away from everything else that is under DHCP. Terraform assigns the IP addresses statically when it brings up the boxes. The Chef that bootstraps the instances knows how to work out what the other IP addresses are, so it can populate the list; Lovely repeatable infrastructure.
So with the Zookeepers happily clustered we are left with Kafka. Having got the tricky Zookeeper IP list out of the way the Kafka problem becomes a little easier to solve in an ASG.
Kafka nodes come up in an ASG and connect to the Zookeeper Consul service (If only Zookeeper was as easy to cluster as Consul) they can then discover the other Kafka instances from Zookeeper and away they go.
Race Conditions
It’s not quite that simple though, the Kafka instances all still need a unique broker ID. To start with we tried doing something clever, the Chef that bootstraps the Kafka instances checks with Zookeeper what broker IDs it has registered and picks the lowest unused one.
This works perfectly… when you only have one box coming up at a time. If you have more than one, the delay between finding the available ID, setting it and bringing up Kafka is long enough to get duplicates, and this is bad. After some fiddling trying to get this to work with random sleeps (yuck) and considering whether to go to the effort of implementing a whole ID locking routine in Ruby, we gave up on that approach and instead decided to just go with automatic broker ID generation. This doesn’t fully solve the problem, since Kafka instances with new brokerIDs will not take on any topic partitions until they are manually requested to move across. But for now it is a good enough solution.
The Migration of DOOM Happy Kittens

Up until this point I had been rather hating Kafka. The whole Zookeeper clustering thing was just awful and Kafka needing zookeeper at all seemed just stupid. Why couldn’t it all just work like Consul!? It is all a bit early-2000s enterprise-y and just doesn’t want to fit in the cloud.
So, after much testing on staging and test environments and developing of a process, migration time came. We were going from the old Terraform EC2 solution with passed through variables, null-resources and temporary files with IDs in to a much simpler static-IP addressed Zookeeper and Kafka in an ASG. Oh and did I mention, there could be no downtime or loss of data? The process was:
- Bring up new Zookeeper cluster.
- Manually join the new Zookeepers with the old ones to form one big cluster.
- Kill off the old Zookeeper instances (Consul service endpoints were used throughout so this worked fine)
- Bring up new Kafka cluster
- Manually move the topics over to the new Kafka instances with their new broker IDs
- Deprecate and kill off the old Kafka nodes.
It worked. The data all moved over. The connections moved over. The new nodes got busy and the old nodes stopped doing anything. Nothing broke when the services on the old nodes were stopped or when terraform destroyed all the old stuff.
Here you can see from our Outlyer monitoring, the messages per broker migrating to the new nodes.
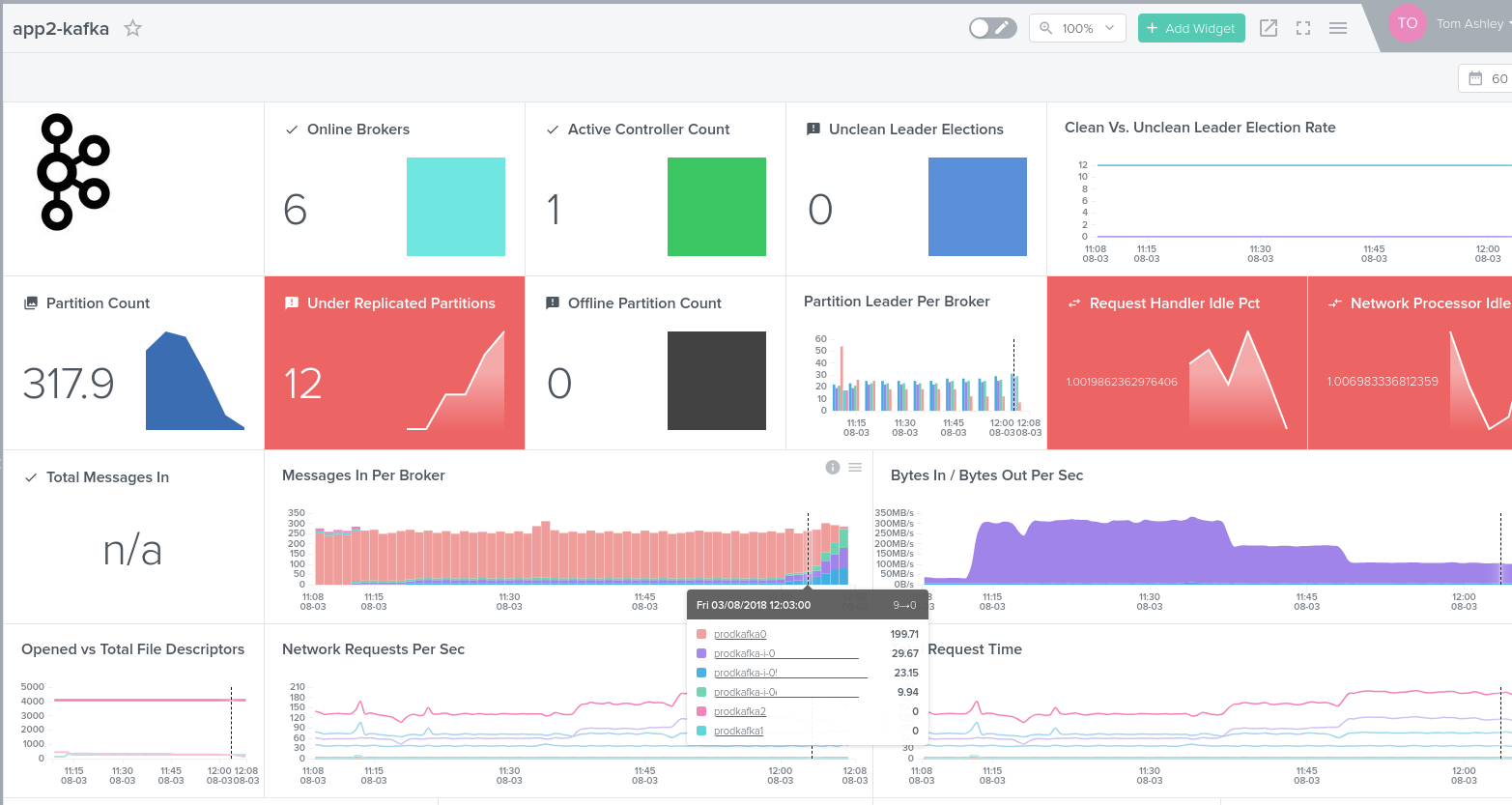
I quite like Kafka now.
Stay tuned for the next part where we take the work here and develop it for our Mongo infrastructure.