Disclaimer: This blog applies to monitoring at SaaS companies.
Monitoring projects are quite common in large organisations. Usually they kick off at the beginning of the year when everyone is fresh and renewed from the holidays. A large block of time is allocated to ‘cleaning up what we have to make it useful’. Everyone dreams of a day when the various systems actually reflect reality.
Unfortunately, it’s not always easy to determine how best to tackle such a project. Sometimes you have upwards of 20 different tools all overlapping in various ways. Perhaps a lot of time has been spent fine tuning them into perfect snowflakes that nobody dares touch.
If you find yourself in such a position here are the things we usually advise.
Consolidate
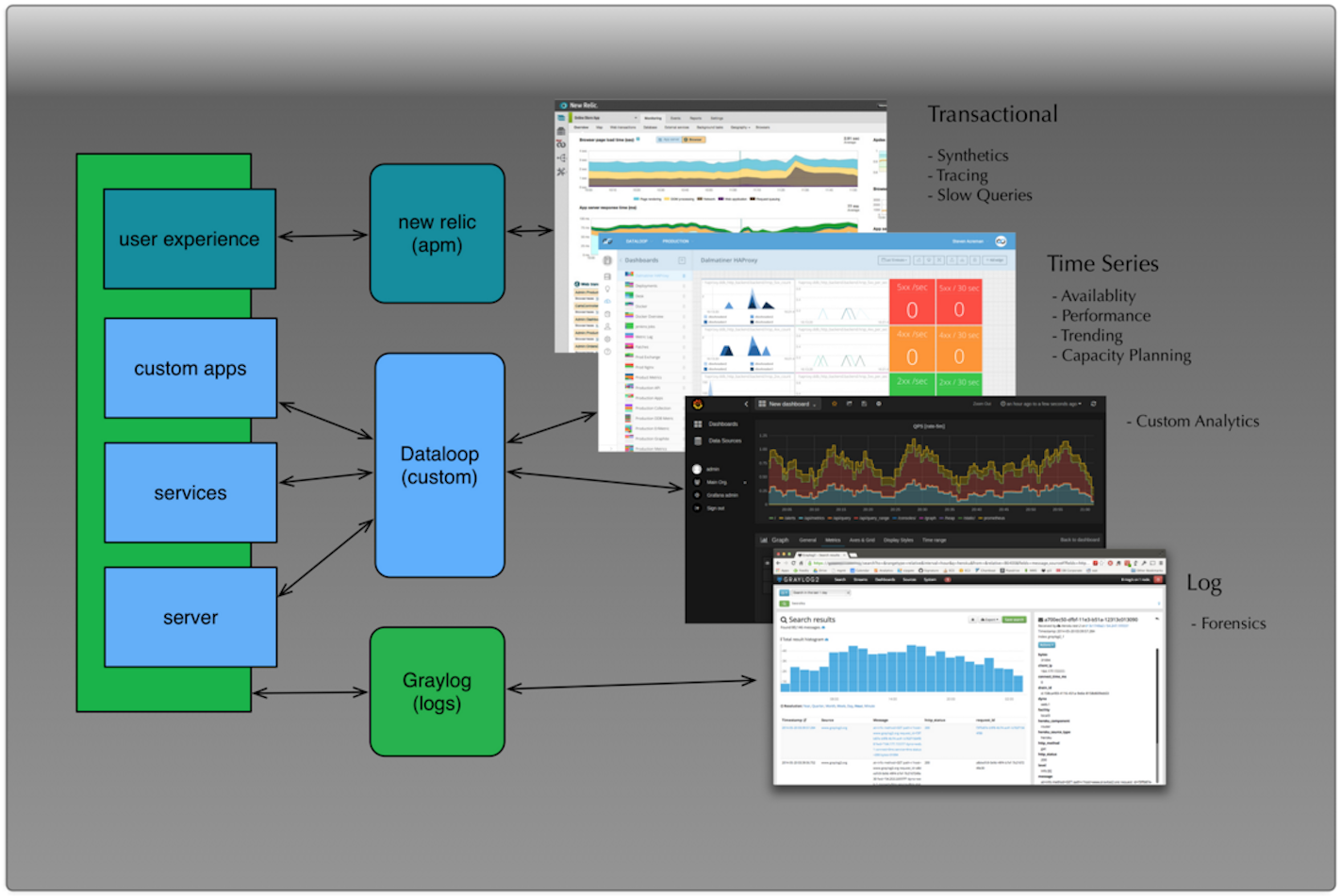
There is no single unified monitoring tool available that does everything well. However, you can reduce the number of tools to a few that can be managed properly. From a high level perspective the core of your project should revolve around:
- Application Performance Monitoring
- Log Monitoring
- Custom Monitoring
Pick one good tool from each of those buckets as the basis for your project and consolidate down into them. If you get those right then everything else is just a feature around the edge.
In the APM space New Relic and AppDynamics are the clear leaders. In many ways this is the easiest bucket to get right as these tools are often very quick to setup and don’t require a lot of ongoing maintenance. The trick to succeeding at this part of the project is to gain adoption with the tooling. There’s no point having APM if the developers refuse to login and use the information to troubleshoot and optimise their applications.
For log monitoring we see a lot of Splunk, ELK and Graylog. Regardless of what you select there is usually quite a large task required to make these tools work properly. It’s always tough to work out whether to fix the logs first or collect everything and fix them second. My advice is to fix what’s going into your log files before you send a bunch of rubbish into your system.
Ultimately, the logs that your applications output need to be high quality and they need to be collected and indexed. Then somebody needs to take the time to sift through them to derive value. This is an ongoing process that can only really be helped by educating the company about correct logging practices.
The custom monitoring space is less well defined. I often explain it to people as being the equivalent of unit tests for environments. When you write software you usually write tests to confirm it is running correctly. Custom monitoring fills this gap for operations and development teams running services.
You need to write custom checks and collect custom data from applications in order to verify it is running correctly. There is nothing that you can buy today that will write good quality unit tests for your code and I doubt there ever will be. The same is true for custom monitoring systems that need to verify a service is running exactly as designed.
You probably have custom monitoring in the form of Nagios, Graphite, StatsD and a bunch of Ruby that the last SysAdmin implemented before he left. You might have numerous installations dotted around and even the odd discrepancy where someone fancied trying Zabbix, Icinga, Shinken, or one of the other hundred tools that can be coerced into running check scripts. Cleaning all of this up can be painful. This is the area that Outlyer works in so we know exactly how hard it is to decommission the old systems and move everything to the new.
Although I am biased as this is a blog from a SaaS monitoring company I honestly think you should consolidate to SaaS monitoring tools. Pick Splunk, New Relic and Datadog, or SumoLogic, AppDynamics and Outlyer, or any combination. Why would I recommend this? Because you get to spend a lot more time on what matters which is actually fixing the monitoring.
Fix the basics
The biggest mistakes we see when starting monitoring projects is the scope. Monitoring always appears to be deceptively simple and the reality is that unless you prioritise the basics you’ll be kicking off yet another large monitoring project next year.
Once you are down to a few tools that are central to your strategy take a look a what you want to achieve from each. APM tools should help to identify performance issues in the code. From experience I’d say that if you have a very motivated dev team then go with New Relic as it’s simple and quick to get going. Developers generally like it and if you are lucky the word spreads and you can wander round and see it open on their 2nd or 3rd monitors. If you have a more reluctant dev team and an ops / devops team pushing for application changes against the weight of a product manager who always campaigns for features then I’d go with AppDynamics. AppDynamics is much more advanced and helps even non developers identify problems which is very useful when arguing for non feature requirements.
For your logging I’d probably get your collection strategy fixed first. You need a reliable way to ship and grok log messages. Start by sending the basic syslog messages in first and clean up or fix anything you find along the way. Then gradually increase coverage. The last time I did this there was an application log getting absolutely hammered by trace messages. This was being masked by some quite efficient log rotation and compression so nobody noticed. You’ll come across a lot of little problems that are easy to solve but would create you a headache if you just dumped every file without looking.
Custom monitoring falls under a couple themes. For the traditional operations related monitoring I can’t stress how important it is to know what servers you actually have. This might sound simple and basic but I’ve encountered some individuals who didn’t care. Knowing what servers you have, which ones are alive and dead, and being able to log into them all is table stakes at the adult game of monitoring poker. If you can’t do those things then cancel the monitoring project and start a ‘SysAdmin 101’ project.
Once you have all of your servers configured in your custom monitoring tool, lets say Nagios for instance since it is the most popular tool around today, you then need to start layering your checks so that you get alerted when every piece of your stack breaks. Things can break in very nuanced ways so you’ll be continually adding little checks to detect the corner cases.
Under the developer theme of custom monitoring it’s incredibly useful to see realtime graphs. The most common tooling here is Graphite and StatsD. Unless people are familiar with these tools there is a bit of education required. You may need to run some training sessions of internal webinars or brown bags to seed the adoption.
Reviewing the results
Let’s say you spend a year getting the above right and end up with just three systems instead of twenty. You have developers using APM, your logs are under control and providing value, and you know exactly what is working and what isn’t in your company. Well, if you reach that stage then you can move off onto doing some more exciting things that build on top of the basics. Or perhaps someone decides to setup some docker hypercluster thing and you’re back to trying to get the basics running on that :)