If you have moved to the AWS Cloud, or are in the process of doing so, chances are you don’t have a great deal of time to worry about monitoring it. Now, ideally there would be an off-the-shelf solution to take this pain away. This was the aim for the AWS CloudWatch service, but we decided to go a step further. Today we are pleased to announce the release of the Outlyer AWS integration.
Complete AWS monitoring in five minutes. Really.
As per the Outlyer tradition, we have made AWS monitoring super simple to set up. You just provide us read-only access to your account by completing a few simple fields, and you are done. We will look up the AWS services you are using and automatically ingest all service and custom metrics you would get with CloudWatch.
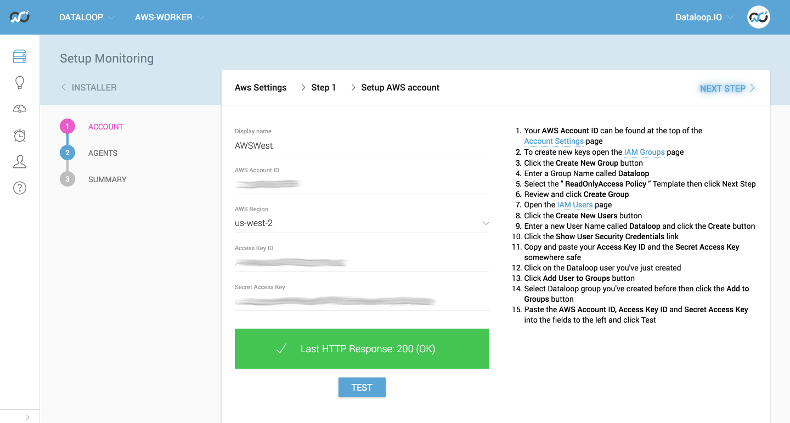
Unfortunately, AWS does not provide CloudWatch metrics for free, but we remove any surprises by giving you an estimate of what AWS will charge.
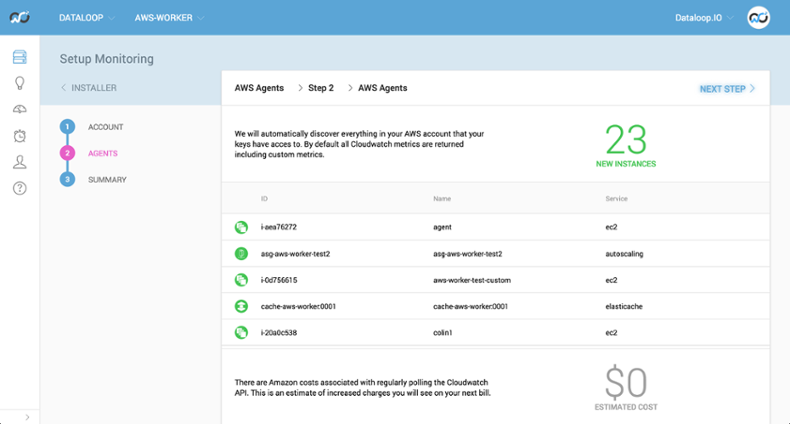
Once we have discovered all of your services, we will automatically set up dashboards and alerts for them. This will give you complete monitoring for your AWS stack.
.png)
We didn’t stop there. You can also install our agent on your EC2 instances for more comprehensive monitoring of your machines. We seamlessly integrate agent and CloudWatch metrics so they are all in one place. Also, because we fully index all metrics from AWS, you can perform the same complex queries as you would with any other metric in Outlyer.
The integration works well with our account model. You can monitor different services or instances in your AWS stack using separate Outlyer team accounts - all under one master account. This is incredibly powerful for delegating the monitoring responsibility to different teams in your organization, while having the overview of your entire operations infrastructure.
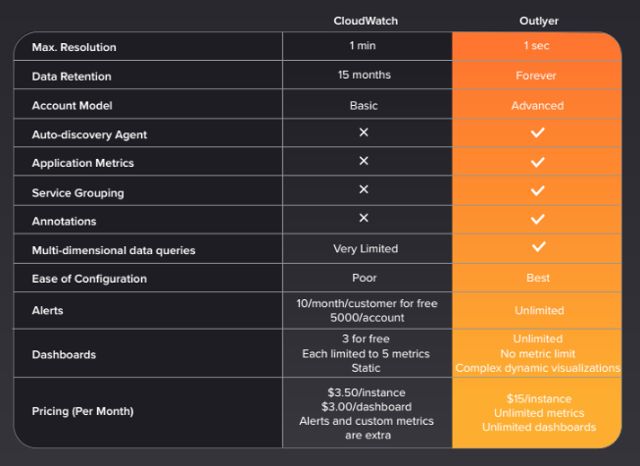
Why not just use CloudWatch?
CloudWatch is a good out-of-the-box solution, but you’ll need additional abilities to understand your cloud performance. Take a look at how we compare.
How we built it
There were four main parts to building the AWS integration.
-
We had to add the ability for agents to be virtual. Previously, all agents in the UI mapped directly to a physical host running our Python-based agent. We needed to visualize the instances inside the AWS service, and they share a lot of common attributes with existing agents, so it made sense to represent them as agents in the UI. Since there is no actual Outlyer agent running on these instances, there are certain features unavailable to them, for example plugin deployment and remote script execution. So, we added the ability to create virtual agents which have these features disabled.
-
Making the user interface simple and easy to use was very important. We spent significant effort refining the setup wizard to make the process simple and informative. We explain how to safely create access keys, what we have detected, and how much monitoring these services will affect your AWS bill. No surprises or confusion.
-
The main body of work was in the AWS backend worker. The Outlyer application is constructed as a set of micro-services, so we added another worker service for AWS. This new worker is responsible just for monitoring all the AWS services. It ensures a virtual agent is created for each of the instances in the AWS services being monitored, and checks their state so that it can alert on failures. The worker also pulls all the CloudWatch metrics for these instances and stores them in our time-series database.
-
The final part was ensuring that this works seamlessly when the Outlyer agent is also installed on the host. All the agents are managed by a different service to the AWS worker, so we needed to ensure some consistency between the two when the Outlyer agent is installed on an AWS instance. After all, we want all the CloudWatch metrics and Outlyer metrics to appear as if they were coming from a single source. We could have solved this by having the services look in the database upon discovering a new instance, to check if it already existed in the system. This solution would have added a lot of extra load and would have meant dealing with potential race conditions. Instead, we opted for generating agent IDs from a hash of the instance details (like instance and account IDs). These details are available through the AWS APIs and via the metadata endpoint exposed on the host. As a result, we can collate all metrics under the same common identifier without having to rely on the database for consistency.
That pretty much summarizes the development work for this feature.
Don’t try this at home, kids
A feature wouldn’t be worth its salt without some war stories. Here are a few of the headaches we ran into whilst working with the AWS APIs.
-
API responses were often inconsistent. There are even inconsistencies with an individual service. For example, DBInstance, DbInstance and Dbi all used as prefixes in the same service: http://docs.aws.amazon.com/AmazonRDS/latest/APIReference/API_DBInstance.html. Based on the way Amazon runs its business (as a collection of independent services), I can understand differences across services. It’s a little harder to understand issues within the same API. Whilst not a huge issue, it is frustrating to have to look these up each time.
-
The rate limits for the services are set painfully low, and also vary across the individual services. We had to spend significant effort to throttle our requests to spread them across a longer period of time.
-
The resolution of data points returned from CloudWatch is far too low to be of great value. For example, one minute (if you pay extra) for EC2, but default is five minutes, and one day for S3. I struggle to see how you can run a production system if you only collect a data point every five minutes, and a point per day is just insane.
-
CloudWatch supports querying across several dimensions (e.g., instance ID, instance type, region, etc). However, the time series are always combined into one, so you are unable to infer the data points which make up the combined series. For this reason we only query by the host, then users can do combined queries inside Outlyer.
-
EC2 instance IDs are not guaranteed to be unique so we need to combine them with other values (like account ID) to get a unique identifier.
-
There is no consistency for resource identifiers. Some services expose Amazon Resource Names (ARN) and some don’t.
Do try this
So, that is our AWS integration. As you can imagine, we spent some time making it as user-friendly and helpful as possible, so please sign up and give it a try — the trial is free and full-featured.