At Outlyer, one of the key trends we’re seeing in the monitoring space, is Microservices. So, are you ready to compete in this Microservices world? Although Microservices tends to be adopted when an online service gets to scale, we’ve also seen smaller services and start-ups (including us) designing their architectures around this concept so they can scale up easily as they grow.
What are Microservices
For those of you new to Microservices, and because there’s several definitions of Micrservices out there, I wanted to clarify what we mean by Microservices here at Outlyer.
At a software/architectural level, Microservices is basically Service-Oriented-Architecture (SOA) done right. Every feature of your online service is run as a discrete service running on separate servers or containers. Taking Just-Eat.com as an example (one of London’s largest online services that are designed around Microservices), you can imagine the different services required to process a take-away online; you need a service to handle the inventory, another for processing the order, another for processing the billing and another one for notifying all the parties of their order and delivery.

The major benefit of this architecture is when done right, every service can be scaled independently as you scale (by adding more servers/containers) and developers can choose the best technology/language for each service. For example at Outlyer all our Microservices are linked together via queues and are written in node.js. However we are potentially looking at Erlang for our metrics workers because of the performance gains we can expect processing all the metrics we receive. Because each component of our architecture is discrete, our developers can rewrite just that part of the service, and should be able to replace our node.js metrics workers with little or no rework required across the rest of our application. The other benefit is issues are easier to diagnose as our service becomes more complex, as with every feature broken into a discrete service our developers have smaller code bases to debug when issues come up.
However the real, real benefits of Microservices is when your team starts growing as you scale. Services are owned by different development teams, who actually own and support their Microservices in production. For example, Spotify has over 100 Microservices, with 24 development teams organized around them (See a great video about it here). Each team is responsible for a selection of the Microservices, and do their own independent releases and support for the services they own.
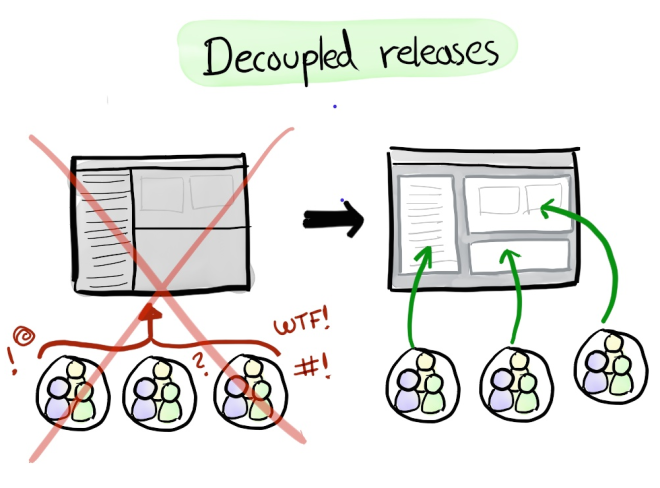
In this model, Operations typically becomes the “platforms” team, providing the common processes and tools shared across the development teams, and also 2nd line support responding to service-wide issues such as major incidents and downtime. However, the development teams themselves are responsible for their own deployments, architecture, and first-line support of their services. This avoids the common issue of Operations not having all the knowledge required to support a complex service and having to wake up developers who wrote the code when a service goes down. Now the development team are the 1st level support, and Operations are only called in when more help is required.
There’s reason why businesses like Google, Netflix, Uber, and Amazon have all migrated to Microservices. They need software that lets them disrupt industries. Companies with multi-billion dollar valuations do not gamble with their software especially if the software is the core of the industry-busting functionality that justifies their high market valuation.
Microservices allow online services to scale by breaking up complexity, they enable greater agility so smaller teams can independently deliver and deploy new functionality, and allow different parts of the service to be scaled up and down independently as load goes up and down leading to better performance and uptime.
The Impact of Microservices on Monitoring
Traditionally, Operations have owned the release and support of online services, which means that all the monitoring tools out there generally support the needs of Operations and a single team. However in Microservices you’re decentralizing the tools and processes out to multiple development teams. The development teams will also include non-Operations people such as developers, QA and product management too.
Hence Monitoring needs to evolve into a self-service tool that allows teams outside Operations to collect, graph and alert off metrics from their own services, while still providing the Operations (or platforms) team a service-wide view of how the service is performing.
In this approach, development teams can get the visibility and alerts they need to support their Microservices in production, while Operations can review their monitoring to consultatively help ensure everyone has the coverage they require, and also work off the same data as the teams when supporting incidents in production.

Because monitoring tools to date haven’t been designed for Microservices, they tend to have a few problems:
- Mo’ Services, Mo’ Problems: As the service is broken up into more and more services, all of which require their own monitoring and alerting, getting good coverage becomes harder, especially as releases (hence change) gets faster. For those that achieve it, they end up having to collect and store significantly more metrics than before leading to scaling issues with their monitoring tools.
- Adoption: In the old world of monolithic services, where Operations were the only real users of monitoring tools, dated UIs and large complex configuration files were acceptable, as everyone was familiar with the common tools like Nagios. However getting people outside Operations to learn and adopt these tools is hard, so they either use other tools for monitoring (i.e. Graphite) or Operations have to invest a lot of effort into “making it easy” with Configuration Management (CM) tools. This leads to a lot of the bespoke, custom solutions we’ve seen proliferating across online services in the past few years, that all take time away from all the other things Operations teams need to worry about, or monitoring silos as different teams use different tools.
- Monitoring Silos: Each team starts bringing in their own monitoring tools because the ones Operations provide don’t work well for them or require a PHD to learn. This leads to Operations looking at one tool (i.e. Nagios), while Developers use another (i.e. Graphite). In many organizations there is a proliferation of Graphite servers setup by development teams for their own monitoring and metrics, which inevitably leads to a project by the platform team to centralize their graphite monitoring so they have a single source of truth everyone can work around, and also get a holistic view of how the service is running.
- Backlog Requests: Developers struggle to get new checks into production as they lack the knowledge and experience of tools like Nagios that Operations have, meaning they end up just creating extra tasks for the Operations team to do for them, adding to their already large backlog.
- User Models: The monitoring tools tend to provide a single user experience, so everyone shares a single login (making it hard to audit changes), or even when they have multiple logins, the tools show everything by default without giving different teams and users their own views into the Micro-Services they care about.
- Pricing models: Although we’ve mentioned a couple of Open-Source tools, many of the SaaS monitoring tools also tend to take a more traditional approach to monitoring. One area in particular is their pricing models. With Micro-Services you tend to use more smaller instances, or even containers, that per-instance are significantly cheaper. Hence although ‘per server’ pricing models are simplest, it only works if the price per server is relative to the cost of hosting the server. No-one is going to pay $150-200/month to monitor a $60/month instance.
Quickly, what starts as a simple requirement: “we need monitoring”, becomes a drawn out custom solution that typically takes 5-6 months (or longer) to implement, and becomes another custom tool that needs supporting and scaling.
We experienced these problems first hand when we ran our own online service at Alfresco. It’s the change in requirements for monitoring tools and Microservices that forces lots of companies to invest significant time and effort customizing their monitoring tools with configuration management, integrations and new custom UIs so that monitoring can be delivered as a self-service solution across their development teams.
A New Set of Requirements for Monitoring
As Microservices become more popular, we need to evolve the requirements we are designing our monitoring tools around in order to save Operations/Platform teams having to spend significant time and effort adapting the current tools to the world of Microservices.
At the core, Monitoring tools need to focus on an area they traditionally have been week at, adoption outside Operations. We need more modern UIs, with a focus on User Experience (UX) design to make it really easy for teams outside Operations like Developers to setup and use their own monitoring as a self-service solution, while still giving Operations the monitoring they need. This includes new user models so multiple users can collaborate around their monitoring metrics and alerts, and not be overwhelmed with 1000’s of metrics, dashboards and alerts from all the other teams’ Micro-Services in the organization.
Outlyer monitoring solution has been specifically engineered to support the DevOps microservices model. And, support for DevOps is an mportant attribute in this model. Outlyer breaks down the silos and bridges the gap between Dev & Ops by providing a self-service monitoring solution in which everyone can make data-driven decisions on how to run a better service for users. Outlyer’s account model suppots role-based access control so different teams can take responsibility for monitoring their own part of the service at any point in the service lifecycle - development through production - while also giving the central operations team end-to-end oversight and control accross all teams.
Get deep visibility across all your services & environments with Outlyer. The ONLY monitoring platform for Microservices built for DevOps.
Start your 14-DAY FREE Trial Today
Make sure you subscribe to our blog or follow us on Twitter to get notified of when they’re published!