Databases are a crazy topic and it seems everyone has an opinion. The trouble is that opinions are like belly buttons: just because everyone has one it doesn’t mean they are useful for anything.
With that in mind, I decided to pen a magnum opus of my own opinions. Something I can point people to next time someone asks ‘have you tried X’?
Disclaimer: Outlyer helps build DalmatinerDB, so there is a massive conflict of interest.
First Publication Date: 26th August 2016
Last Updated: 28th August 2016
Top10 Time Series Databases
Runners Up
Raw Data
The contents of this blog post are based on a big spreadsheet I lovingly hand-crafted over two evenings. My advice is to browse the table and if you are still interested, then continue to read this post.
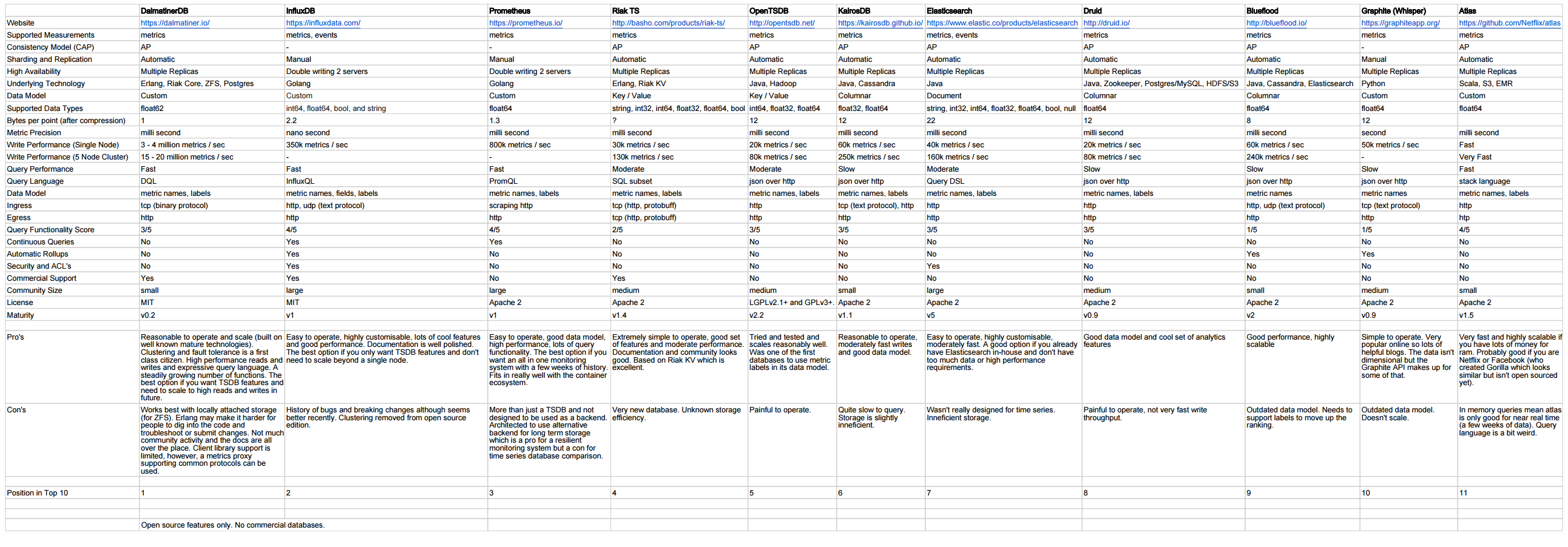
The spreadsheet is here for those not wanting to zoom in on the tiny text (read-only webpage version):
https://docs.google.com/spreadsheets/d/1sMQe9oOKhMhIVw9WmuCEWdPtAoccJ4a-IuZv4fXDHxM/pubhtml
For those who want to see it in a proper Google sheet and make contributions via comments use this link:
https://docs.google.com/spreadsheets/d/1sMQe9oOKhMhIVw9WmuCEWdPtAoccJ4a-IuZv4fXDHxM/edit#gid=0
If you have any recommendations for additional things to compare you can also leave a message below. The raw data is probably just as useful as this summary blog if you are evaluating time series databases based on your own unique set of criteria.
Big thank you to Heinz Gies and Brian Brazil for help creating this.
Context
I am only interested in time series databases for use by developers and operations people to store and retrieve data that pertains to the health and performance of the services that they build and operate.
Every time series database in this blog will be judged based on their suitability for that task. If you wish to debate a different context then please take the underlying data, rearrange it, add your opinion and release a different blog post.
I believe the number of metrics being collected from infrastructure and code is going to rise dramatically over the next few years. Therefore this blog has a heavy bias towards databases with a dimensional data model and those that can either scale beyond a single node, or are so highly efficient it makes up for having to manually shard them.
For operational monitoring you can afford to lose some data without it affecting the usefulness of the system. You’re mostly looking for trends and patterns and the odd gap here and there doesn’t matter too much. You do however want it to be low latency and highly available otherwise it becomes frustrating to use during an incident.
Time series data has certain qualities to it. It’s usually write once and requires a balance of high read and write performance. There are also a bunch of common analytics functions people want to run. Could you do it all in MySQL or Postgres? Possibly, but you’d have to write a lot of code to add the functionality many of these databases already provide.
Scope
I set some rules to attempt to limit the scope, otherwise this blog post would never end.
-
Only free and open source time series databases and their features have been compared. Therefore if someone asks “have you tried Kdb+ or Informix?” the answer will be no. They are probably awesome though.
-
The list will only include databases that either classify themselves in their marketing material as time series, or have been written about in a blog by a cool company as something they are using for time series data.
-
I’m only going to accept additional suggestions that change the top 10 if they are actually useful within the context of this blog post. This means they can handle hundreds of thousands of writes per second with reasonable query performance and have a data model that includes labels.
Caveats
I’ve tried a handful of the top 10 databases and have a good amount of experience with them. The raw data was reviewed by Heinz Geis who has tried others, particularly the Cassandra-backed ones, in the past. Testing, validating claims and checking sources in a professional way like a true journalist hasn’t been done. What has been done is reading the official docs, reading StackOverflow, looking through GitHub issues and code, and generally hacking the information together. Over time I expect the raw data to become more correct based on peer review, and I’ll do my best to update this blog to reflect that.
With this in mind, some facts may be incorrect. If anyone spots anything factually wrong, please let us know.
Benchmarking figures are based on published results from each project or company. Where these were not available figures have been taken from results found in online searches. Although some are available online with steps to recreate, some are not.
Why didn’t this blog include several years of benchmarking results performed across all standardised hardware on a common data set? Because benchmarking is a sizeable chunk of work, prone to error, and not the full story anyway.
The numbers listed are highly favourable to most databases. They are either the numbers blogged about or claimed at some time in the past. If you feel any numbers are wrong let me know and I’ll update them.
The way I’d like to see benchmarking work is that you get to choose the highest powered server you can possibly lay your hands on. Then set up a reasonable real world test, like firing in 6000 metrics per agent over 500 agents at 1 second granularity (3 million metrics per second) and seeing if queries still work. Benchmarking reads is even more subjective so I wussied out and just went for fast, moderate and slow.
If you’d like to reproduce the DalmatinerDB benchmark the Gist is here:
https://gist.github.com/sacreman/b77eb561270e19ca973dd5055270fb28
InfluxDB also has a number of papers you can download here:
https://influxdata.com/technical-papers/
As it has worked out there are several orders of magnitude difference between the benchmarks of the top 3 databases and everything else. So even if they are wrong by a large margin they at least provide a sense of scale of difference for comparison.
Another subjective row is the query functionality score. I took 5 as the max score and gave Prometheus 5/5 for being awesome. Everything else was compared against that score and based on power, expressiveness and wealth of cool functions.
Observations
All of the TSDBs are eventually consistent with the exception of Elasticsearch which tries to be consistent but fails in the true sense of the definition. This means that if your use case for time series data means you need to guaranteed storage of every point then you will probably need to write your own time series layer on top of something like MySQL or Postgres.
Databases built from the ground up for time series data are significantly faster than those that sit on top of non purpose built databases like Riak KV, Cassandra and Hadoop.
Performing queries across billions of metrics looking for labels that only match a few of them (a common scenario with time series data at scale) is really slow in Cassandra. This is because of the way it stores data in columns. This extends to any columnar database including Google’s BigQuery which all have a natural disadvantage with time series data.
Storage efficiency is extremely important. The purpose built TSDB’s only consume a few bytes of storage per data point. Why this is important becomes clear when you start to add up the costs.
Let’s say you have 1 server, and you want to record a single metric for its overall cpu % utilisation over a year at a 1 second interval. That’s 31,536,000 points that need to be stored. With DalmatinerDB that takes up 31mb on disk and at the other end of the scale it would use 693mb of space on disk with Elasticsearch.
Now let’s say you are crazy enough to actually be storing 3 million metrics per second. With DalmatinerDB that’s 93Tb of disk space needed for a years worth of data. With Elasticsearch it’s just over 2Pb. On S3 that would be the difference of $3k per month vs $63k per month and unfortunately SSD’s (which is what most time series databases run on) are magnitudes pricier than cloud storage. Now factor in replication and you’re in a world of pain.
Results
There are some pro’s and con’s listed in the spreadsheet for each database. I’ll elaborate a bit on those below for each database.
DalmatinerDB - First Place
When I was searching for the best time series database I wanted something fast, that would be easy to scale and operate, and that wouldn’t lose all of my data. It also needed to support a dimensional data model and expressive query language with a variety of functions. No such thing existed at the time so we took DalmatinerDB into the back of a aircraft hanger, played some A-Team music and about a year later we have a rocket powered tank.
DalmatinerDB is at least 2 - 3 times faster for writes than any other TSDB in the list. It can write millions of points per second on a single node compared to some databases that can only manage a few tens of thousands.
Query performance is also good and can be split out and scaled independently with multiple query engines. Metadata lookups (queries across labels) are handled by Postgres which is blazingly fast.
The DalmatinerDB storage engine, which was designed around the properties of the ZFS filesystem, has the best storage efficiency out of any in the list. Because DalmatinerDB is based on Riak Core you get all of the benefit of the riak command line utilities. You can cluster join, plan and commit and watch the usual rebalancing magic happen as data automatically shifts around the ring.
The query language is very similar to SQL and is comparable to the other top TSDB’s. Additional work is under way to increase the number of available functions to match InfluxDB and Prometheus.
There are some downsides. Although the code is clean and small, as it relies on mature technologies for the heavy lifting, it is written in Erlang which puts off some people from contributing. Also, it has been in production for a couple of years at a few large companies monitoring Project Fifo cloud orchestration platforms. It has been stable and in production at Outlyer for over a year.
The past few weeks have been spent bringing the community open source code 100% in sync and packaged to work on Linux. So while the code is stable and well tested, the docs and the user experience needs to be worked on a bit. We’ll release a blog on exactly how to setup DalmatinerDB on Ubuntu 16.04 very soon. The other problem some people had was with the highly efficient binary protocol for getting the data in. We have a few more client libraries now, as well as a metrics proxy which will convert various metric formats like OpenTSDB line protocol into DalmatinerDB. There’s also a good quality Grafana 3 data source plugin.
InfluxDB - Second Place
It got a lot of bashing recently on Hacker News for the decision to discontinue development of the clustering features and instead make them a paid option. However, I believe it’s still the next best option after DalmatinerDB. In another couple of years, had the clustering remained and been proven reliable and efficient through lots of peer review and testing, like what happened with Riak Core and Cassandra, it could have been the defacto best choice. It’s pretty fast on a single node and has a lot of very cool features and efficient storage. If I knew my data would always fit within a single node it would probably be number 1 on this list. InfluxDB uses an SQL style query language which is easy to get started with.
Prometheus - Third Place
It’s a bit unfair to rank Prometheus on this list. Prometheus is a great monitoring system with a very cool time series database built-in for local storage. Prometheus is incredibly fast and has been highly optimised for querying large quantities of time series data across many dimensions. It uses varbit encoding to get down to 1.3 bytes per data point. I’m not entirely sure how you would use Prometheus as solely a time series database as it was never designed for that use case. I guess you’d have to scrape an api that was connected to a queue and manually shard. That would make for a fairly quirky architecture but could be fun. Prometheus is 3rd place because quite frankly, even though it wasn’t designed to be a time series database, it’s still better than most other options. The query language used in Prometheus is the gold standard against which I’ve compared all other databases.
Riak TS - Fourth Place
This is a very new database and the docs don’t provide good benchmark numbers. I had to pluck some numbers out of someones presentation on Slideshare. The storage efficiency is also a complete unknown. This does however look like quite a good all-rounder. It’s moderately fast, has a lot of flexibility baked into the schema design and the query language looks good. It’s based on Riak KV (which itself is built on Riak Core). This is the first of the databases that weren’t built from the ground up for time series and is a layer on top of something else. I read there has been a lot of work done optimising the write paths and as it evolves over time I’m sure it will start moving up the list.
OpenTSDB - Fifth Place
Old reliable. You can find lots of information online and it’s generally agreed that running a Hadoop stack is not enjoyable. The prospect is similar to being asked to run OpenStack or jumping out of a plane with no parachute into a net. However, it works and scales beyond a single node, and when compared to the other options starts to look almost worth doing. If you have Hadoop in-house already then the decision becomes slightly easier.
KairosDB - Sixth Place
The first of the TSDB’s built on Cassandra. This is probably the best of bunch although as mentioned above it’s not very good for querying large quantities of dimensional data. Beyond a certain number of labels queries are going to start eating up all of the memory and timing out. If used carefully and at lower volumes it could be a good choice.
Elasticsearch - Seventh Place
This isn’t really a TSDB. However, when some people have a hammer they use it for everything. It’s one of those things that shouldn’t be done, but to be honest, in some circumstances, it works. If you already have Elasticsearch and have a bunch of spare space, and your metrics per second are reasonably low then why not.
Druid - Eighth Place
Running Zookeeper and HDFS wouldn’t be my first choice. Druid is a powerful analytics database and seems best suited for providing fast queries over a large quantity of data. It’s pretty slow to push metrics into Druid and for the types of queries operations and developers do across millions of labels I’m not convinced it would be nice to use at scale.
Blueflood - Ninth Place
The Blueflood docs seem to mostly consist of a half updated GitHub wiki page. The reason Blueflood is so far down the list is because I couldn’t work out whether it supported labels. My suspicion is that it doesn’t and therefore while being a good replacement for Graphite it doesn’t really fit in with the other TSDB’s with more powerful data models. Blueflood is also based on Cassandra but uses Elasticsearch as an index. It seems there was some talk about adding labels in the past, so if anyone knows if that happened, let me know and I’ll re-evaluate the score.
Graphite (Whisper) - Tenth Place
This is the poster child for the past generation of time series databases. More powerful than RRD was when it first came out but now quite outdated. Add to that the fact that it doesn’t scale. I’ve read the blog that shows how to scale it and still came away thinking it didn’t really scale. It’s on the list because it was amazing 5 years ago and did a lot to get people graphing things.
Runners-Up Results
Atlas
There are a couple of databases in use at very large companies. Netlix has Atlas and Facebook has Gorilla. Both took the approach that they had vast quantities of metrics coming out of their systems and to scale their monitoring system the only practical choice was to build an in memory clustered time series database. I’m not entirely sure how practical these TSDB’s are outside of the mega companies. From reading the Atlas Github issues list it seems some people would quite like to implement long term storage on disk.
Chronix Server
I got a bit excited when I first saw Chronix Server. It has some very cool new ideas around storage compression and some of the features for searching for ‘similar’ metrics warrant an afternoons worth of playing. Chronix is a very new project and probably belongs in the Top 10 list. My only worry currently is that it’s based on Solr and the advertised 30ms to return a metric point is pretty slow. On the other hand there are some comparison tables that state it’s faster than InfluxDB for some queries. Will do more investigation and then work out its true position.
Hawkular
Another time series database written on top of Cassandra and this time by Redhat. I couldn’t see anything that made it stand out above KairosDB. It’s probably better than Blueflood given the support for metric labels. I also found NewTS on my last evenings worth of internet searching which was written by the guys at OpenNMS. It seems there is a never ending supply of time series databases being written on top of Cassandra. Unless any of them are significantly better than KairosDB I’m not going to change the top 10.
Warp 10
This is a very cool database for IoT and sensors. It’s only a runner up here as I set the context as devops monitoring. If I was doing location based monitoring that needed a bunch of complex analytics this would be the first thing I’d setup to test.
Heroic
Another database written on top of Cassandra except I’ve given this one its own spot because it has some clever stuff. Spotify (the creators of Heroic) have regional data centres like a lot of companies and so run a Kafka cluster in each which they send their metrics into. They then have clusters of Heroic databases which are a mix of Cassandra for the storage and Elasticsearch for the indexes, events and suggestions data.
All pretty standard so far, I think SignalFX have a similar setup they have blogged about in the past. What is really cool is that they can federate them all together so they look like that elusive ‘single pane of glass’ that salesmen always describe. If a cluster goes down then you just lose visibility over that piece. I thought that was cool anyway.
The other interesting bit is their use of suggestions and semantec metadata to help users navigate their way through lots of data.
Heroic is cool enough to place in the top 10 if it was a bit more mature. Quite frankly it needs a bigger community. The fact you need to run Cassandra, Elasticsearch, Kafka and Zookeeper with no assurance from any benchmarking blogs that it’s all going to scale nicely is a bit daunting.
The commit graph also looks a bit anaemic since march. If it gets a sudden infusion of contributors and starts looking a bit healther with more blogs describing what it’s like at scale I’d bump one off the top 10 and put that in its place.
Akumuli
A time series database written in C++ with the design goal of being standalone. You can do some very efficient things when you don’t need to reason about distributed systems. This database falls outside of my Top 10 list given the context outlined above, however, this database is pretty cool nonetheless.
It’s the closest thing to DalmatinerDB in terms of performance. A lot of work has been put into making the storage efficient and at 2.5 bytes per point it’s pretty good. It was a refreshing change to see benchmarks and per data point size clearly listed. For most databases I’ve had to muddle through various documents and try to calculate those things from all over the place.
Using the redis protocol to input data and a simple rest api to query keeps things simple. There are various query functions, although not as many as some databases. It does have some cool anomaly stuff baked in though.
If I was building a C++ app and needed some local storage for time series data this would be the one I’d try first.
Conclusion
I had fun reading up on a few databases I’d not tried before. The information was scattered around so it’s nice to have it all in a single comparison table now. Whether you agree with my ranking or not is another matter. I fully expect people to disagree. If you do, then please leave a note with your reasons. Also, I expect a few mistakes. If there are any, I assure you it was incompetence and not malice.
Heinz and I are talking about DalmatinerDB at the Erlang User Conference in Stockholm on the 8th September and we plan to release a bunch of Dalmatiner docs and packages for Linux before then.