Knowledge is a powerful thing and a good monitoring solution should provide a wealth of data to help drive highly intelligent decisions. To subtly complicate things there is a keen distinction between monitoring (observing) and alerting (notifying). Monitoring and alerting are intrinsically linked but they should be looked at separately which I’ll attempt to cover in a future blog post. Without going too deeply into that there is a basic question to be answered.
What..
In most server monitoring tools you have the usual cliche checks like cpu, memory, disk space and a whole host of operating system counters. Layered on top you’ll add application service level checks and maybe even integrate some of the cool APM tools to peer inside the app container and extract some code level metrics. Then you might start to add in log management tools and before you know it you’re left with a vast array of systems to manage and I’m not totally convinced the question has been answered.
Instead of getting led down the garden path by software, what happens if we step back a level and decide what’s important for us to know and in what context? What do I mean by context? Consider how the people that come to your desk or customers enquire about systems that are down, or how you would talk to a non technical manager when describing a problem in a particular area. They typically won’t come to you and ask what’s wrong with the CPU Steal Time on PRODESX1. They probably do care that XYZ system is slow and may understand when you frame the answer in terms of utilisation and capacity of certain high level components.
So how do we go about choosing what? Pen and paper is usually my preferred method. A whiteboard works well when brainstorming in a group of people. Spreadsheets are generally useful after you’ve done your initial version. I’d personally steer away from drawing programs as this stuff changes quite frequently and nothing really matches the agility of crumpling up paper and getting a new sheet from the printer drawer.
Here’s an example of my scribblings:
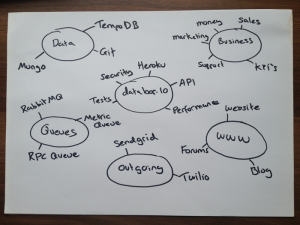
The picture of how I view things changes over time. When people ask me about the state of things in their own semi technical language it changes how I group things at the 10,000ft level.
So what do I think is important for Outlyer? Clearly to me the most important thing is our service. SaaS companies live and die by the quality of their product and bugs or a bad user experience are the quickest way to commit commercial suicide. At a high level, if there is a problem with our API, our site performance, our hosting provider or if our tests are failing I want to know about it in the context of our service. Once I know the context I need to be able to drill down and immediately see what component has the issue and focus on getting it working again. You may notice that I’ve added security as a component.. this was after an awesome presentation by Gareth Rushgrove at Monitorama EU that talked about treating security as a first class citizen alongside QA tests and Ops monitoring scripts.
What are the other boxes? Many of them are linked to the app like our queues and 3rd party services. If I look on my screen one morning and see my Outlyer and outgoing blocks are both red I’m going to know almost immediately that there’s a problem with notifying people. I’m going to drill down into each and hopefully get a good idea of what components are broken. At this point I’ll log into the app and narrow in on that particular area to make sure that the map fits the terrain as Coda Hale would put it. There’s nothing worse than fixing something that isn’t broken, and we need to improve our map if the alerts don’t represent reality or fear losing confidence in the system.
Alongside our service we also have another couple of critical areas that I want to know about. One is our business and the other is our websites that help us communicate with customers. Clearly it’s important for any business to have some cash in the bank. For us as a startup it’s the difference between staying and doing what we love or splitting up and going contracting (don’t worry, we have at least a years worth of money in the bank). We create internal goals for ourselves related to our sales pipeline, the number of validation interviews we’ve done and even how many blog posts we’ve written. We find that by measuring something we can focus on it more because it’s always readily available immediately in a graphical format we can discuss. Pretty much all of our systems are SaaS based and they all have an API that we can suck metrics out of, so putting all of this information into one place and alerting on it makes life much easier. I can now login to a single place and know the health of every part of the business.
In subsequent blog posts I’ll write about how we monitor all of these things. I’ve alluded to how easy it is to write Nagios plugins in previous blog posts. The purpose of this post was to put forward the idea that monitoring can be declarative and you should open up what you are monitoring to everything that is important, and not just enable stuff because a vendor has put it in their app. Go into your monitoring design with your eyes wide open. You should be monitoring what you care about regardless of whether you own a system or not. People will come to your desk to ask if Salesforce is down even if you can’t fix it so it’s great to be able to tell them exactly what’s wrong and perhaps even alert other teams (or the vendor). In future we’ll also talk about how we get some of this information into personalised dashboards that are tailored towards different groups of people, especially power users in different parts of the business. You can drive some real productivity gains by providing people with contextual data that helps them do their jobs better.
Wrapping up
Whatever you decide to do with your monitoring there is no silver bullet. You will always end up with a myriad of tools that perform a particular job well. What can be avoided is wasting too much time on what we call in the trade ‘technical masturbation’. This is where you spend all day configuring stuff that isn’t really providing any real business value.
At Outlyer we’re planning to release a service in early 2014 that makes the entire process that I’ve outlined above quick and easy.
You can quickly draw up your 10,000ft blocks onto our setup page and drill down to create component groupings with a few clicks. You can create, edit, deploy, run and debug your checks from our interface using our advanced editor. Drag everything that you want to monitor into their blocks and start to build out an intense level of coverage that tells you everything you need to know. Once you have it all setup perfectly then you can start to open up the information to a wider audience through dashboards and email reports. We’ll let you tailor these to exactly fit the data that each person cares about rather than the usual generic information that you get from server monitoring tools. On top of all of this you’ll get in-context interactive alerts for items that you want to get alerted on, and we’ll remove that pain of receiving a million Nagios alerts which I’m sure many of you have felt.
Sign up on our website to get notified when we launch.