Back in 2011, a few people started complaining about how monitoring sucked with the #monitoringsucks hashtag appearing on Twitter. Since then a lot of DevOps people have joined the rally. However, more recently, #monitoringlove has appeared after a few open-source efforts—most notably Sensu—to improve the state of monitoring.
The question we asked when starting Outlyer was: does monitoring still suck enough to take the enormous effort of launching a new company in this space?
As anyone who’s done a startup before knows, the last thing you want to do is spend three or more years of your life solving a problem that’s not really a problem. So, we spent the last ten months talking to as many DevOps & operations teams as we could to see if things have improved since 2011.
In the process we’ve spoken to 60 companies (and counting), all of which run cloud services, and some of which are among the largest cloud companies in London, UK. I can’t name names right now as we promised to keep all our discussions confidential, but it is pretty clear what the answer is to the main question we had:
Yes, monitoring still sucks & it’s going to get a lot worse.
What Everyone’s Currently Using
Although a lot of new tools have arrived since 2011, it’s clear that older open source tools like Nagios, and Nagios alternatives like Zabbix and Icinga, still dominate the market, with *70% of the companies we spoke to still using these tools for their core monitoring & alerting.
Around 70% of the companies used more than one monitoring tool, with most using an average of two. Nagios/Graphite configurations were most common, with many also using New Relic. However, only two of the companies we spoke to actually paid for New Relic, with most of the companies using the free version as they found the paid version too expensive.
In the “other” category, there were a lot of different tools with no particular one standing out. Types of tools that fell into this category were SaaS monitoring tools such as Librato & Datadog, used by several smaller start-ups, or many older open source tools like Cacti or Munin. Some AWS users rely on CloudWatch, and there were even a few custom built solutions.
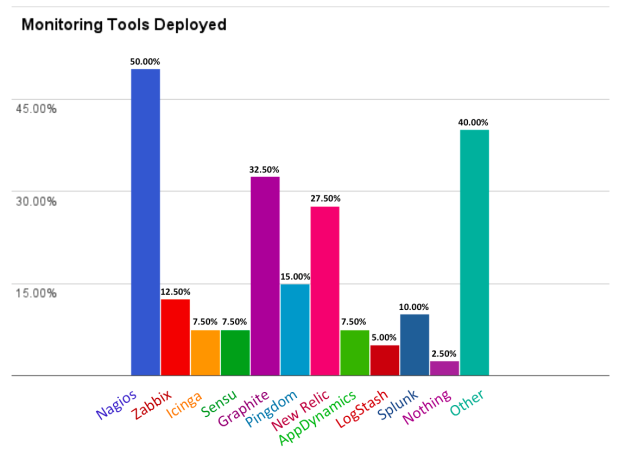
Graph 1: Percentage of companies with monitoring tools deployed.
If we look at tool usage versus the number of servers the companies manage (< 20 being new startup services, and all the way to > 1000 servers for the large online services), you can see that the proportion of older open source tools like Nagios, or paid on-premise tools goes up as the service gets larger, whereas the smaller, newer services are more likely to use developer focused tools like Graphite, LogStash and New Relic.
This makes sense, as many of the larger services are older (> 5 years old) so have legacy monitoring infrastructure, and also have the resources to hire a dedicated operations team who tend to bring in the tools their most familiar with, namely Nagios or Nagios alternatives. They also have more money to pay for monitoring tools like Splunk (which everyone would love to have if they could afford it) or AppDynamics.
The newer smaller services tend not to have any DevOps/Operations people in their company, so developers tend to use simpler-to-install SaaS monitoring tools, or tools that help them such as Graphite or LogStash. There seems to be a tipping point between 50-100 servers when the company has the resources to bring in a DevOps/Operations person or team and they start bringing in the infrastructure monitoring tools like Nagios to provide the coverage they need.

Graph 2: Tool Usage vs. Number of Servers Managed.
Key Trends
While a lot of issues and trends came out in our open end discussions with companies, it was clear monitoring was a hot topic for many of the people we spoke to, and there were a few key issues/trends we saw across the board.
Everyone’s still building kit cars
 As you can see in the data above, companies use an average of 2 monitoring tools to ensure they get the coverage required across different parts of the stack
(infrastructure, application, logs etc.). In some of the larger services it wasn’t uncommon to find 4-5 monitoring solutions in place, for example Nagios for
alerting, Graphite for dashboards, StatsD for developer metrics, collectD for service metrics and LogStash/Kibana for logs.
As you can see in the data above, companies use an average of 2 monitoring tools to ensure they get the coverage required across different parts of the stack
(infrastructure, application, logs etc.). In some of the larger services it wasn’t uncommon to find 4-5 monitoring solutions in place, for example Nagios for
alerting, Graphite for dashboards, StatsD for developer metrics, collectD for service metrics and LogStash/Kibana for logs.
In every company with more than 50 servers, everyone shared the same experience we had had at Alfresco - building a “kit car” of open source monitoring infrastructure over several months. In addition to setting up, integrating and fine tuning all the tools together, many had invested significant effort into writing their own custom infrastructure to address gaps in the tools themselves. For example, one company had spent 4 months writing puppet modules to automatically register new servers and plugins with Zabbix, and fixing scalability issues with the tool.
In addition, many companies had developed their own custom dashboards to display metrics on the large TV screens they had around the office. While most of these were pretty standard dashboards, one particularly (and very cool!) example was a Star Trek status dashboard that showed Nagios alerts with alert sounds from the films.
Most of the people we spoke to understood that investing significant time into building their custom “kit cars” (which then had to be maintained after) created a bottleneck when monitoring requirements changed, especially in high-growth services, and diverted a lot of their time and attention from working on higher value tasks such as getting faster deployments or moving the service to new scalable architectures.
When we asked them why they didn’t use some of the new out-the-box SaaS monitoring services out there instead of building the “kit car” themselves, many people found the newer services lacked the flexibility of open source solutions with their ability to customize them to their requirements, and didn’t like the idea of learning a proprietary system with its own plugin design and features, leading to vendor lock-in. Also, companies in the regulated sectors like financial services or the online gaming industry (of which there are many in London) had strict requirements on what data could be sent outside their service, and found that they cannot use SaaS solutions like New Relic, which by default sends almost everything to their service.
Decentralizing with Microservices
 A key trend we saw, especially as the services became larger, was the move towards microservices, with different cross-functional development teams building,
deploying and supporting their own parts of the service, as Spotify describes for their company in this paper.
While many of the companies we spoke to were some way off achieving this model in their own organization, they were making strategic moves towards it, and they all agreed that
the current monitoring tools available, both new and old, would not adapt to this model.
A key trend we saw, especially as the services became larger, was the move towards microservices, with different cross-functional development teams building,
deploying and supporting their own parts of the service, as Spotify describes for their company in this paper.
While many of the companies we spoke to were some way off achieving this model in their own organization, they were making strategic moves towards it, and they all agreed that
the current monitoring tools available, both new and old, would not adapt to this model.
In this model, the DevOps/Operations team no longer control all the deployments and infrastructure, but instead become a support team to the rest of the organization, providing the tools and processes each team needs to roll out and support their own microservices. A microservice in Spotify could be the playlist service, or the music streaming service— essentially a discrete part of the overall service that provides functionality to end users or other micro-services. This architecture and organization enables a large, complex service to become highly scalable as it grows. However, it dramatically increases the number of servers and services the DevOps/Operations team needs to support, so the only way to scale it is move support to the development teams themselves, who become the first line of support when things go wrong.
This means that the development teams need monitoring for the services they own, with the ability to add and remove checks as the service changes, and customize what alerts they receive and what dashboards they view.
To everyone we spoke to’s current knowledge, none of the monitoring tools available today cater for this model, as they’ve all been designed for the traditional centralized model, where the development team throw it over the wall to the DevOps/Operations team to deploy and support the entire service in production. Current tools aren’t easy to use, they don’t provide the nice GUI that developers want to configure their monitoring, they don’t make it easy for different teams to create and roll out their own monitoring checks, nor do they easily configure their own alerting and dashboards (everyone’s currently receiving everyone’s alerts leading to the next major problem we saw).
In addition, some of the more developer-friendly tools like New Relic have a business model that is too expensive for companies moving to microservices. When a service that is currently only 50 servers evolves into 100s of smaller instances running microservices, with each instance costing only $60/month to run on AWS, $200/agent/month really doesn’t make sense.
Spammy Alerts
And finally, if there was one consistent complaint from all the companies we spoke to, it was alerting. “Alert fatigue” or “spammy alerts”: it’s clear that none of the tools, even the monitoring tools that claim to have advanced machine learning algorithms, have solved this problem, and it’s getting worse as companies scale out even more servers to run microservices on continuously changing cloud environments. In one company’s case, they were receiving around 5000 alert emails a day. With that volume, alerting had just become noise, and most of the team just filtered them out into a folder or automatically deleted them altogether.
A key reason we saw for spammy alerts was the lack of granularity with current tools sending alerts. With many more services and servers, ultimately there are many more alerts being created by the monitoring tools. However, many of the alerts were sent to everyone via a group email address, as the tools didn’t provide an easy way to allow different developers to only receive, or subscribe, to the alerts they cared about. While everyone we spoke to was interested in the potential of predictive & more intelligent alerting using machine learning (particularly anomaly detection as the number of metrics they monitored increased), we believe there are some simpler things that can be done to reduce spammy alerts in many organizations, most notably only sending alerts to the people who need them.
Our Conclusion
Many of the companies we spoke to initially told us their monitoring was “good enough”. They knew the current tools “sucked”, they weren’t designed for the type of services they’re running today and wouldn’t scale, but many had already made the significant investment to address these issues with custom infrastructure in Puppet/Chef to make it work for their needs. However, as we dug deeper and became more familiar with the problems, we saw that many of the issues stated above actually resonated with many of the companies we spoke to. They were very aware that current monitoring solutions were not designed for where they wanted to go: decentralized micro-ervices running on continuously changing cloud infrastructure.
We believe this is the big trend that will change the way monitoring tools are designed for companies running cloud services, and will require a fundamental rethink around how monitoring is managed and deployed across organizations. It will require a way to bridge the needs of the DevOps/operations teams with the development teams they support, and new solutions that allow decentralized teams to monitor and manage their own microservices.
Overall conclusion: with 70% of companies still running the same tools available back in 2011, it is clear that for most monitoring still sucks. Things have overall improved, with many new ideas and tools trying to solve the problems raised in 2011. The issue we see, however, is that they’re all solving the problems from 2011, and not the issues companies are facing as we move into the world of DevOps and decentralized microservices. Without new ideas and ways of thinking about the new challenges, we risk being in the same place in 2020, where monitoring not only sucks, but is even worse than before.
If you’re interested in seeing how we are thinking and doing things differently, feel free to sign up for a free and full-featured trial.